Introduction:
This lab introduced students to the process of geocoding various locations in ArcGIS using both automated program processes and the process of manually assessing and placing geocoded points based on the PLSS addresses of approximately nineteen sand mine locations in Western Wisconsin. The lab works to accompany an ongoing class community project seeks to ultimately develop a suitability/ risk model for sand mining in Western Wisconsin, and more specifically, in Trempealeau county.
The assignment ultimately entailed five key objectives:
- Obtaining and normalizing the data address table
- Auto-geocoding the mines using the ArcGIS geocoding toolbar and geocoding services provided by ESRI
- Adding the Public Land Survey System (PLSS) base data layers through the University's SQL server
- Manually locating/re-locating mines using the PLSS system description and previously added PLSS base data layers
- Comparing the location results to actual placement data and the overall class collective
Methods:
 |
| Figure 1: Original Excel Data |
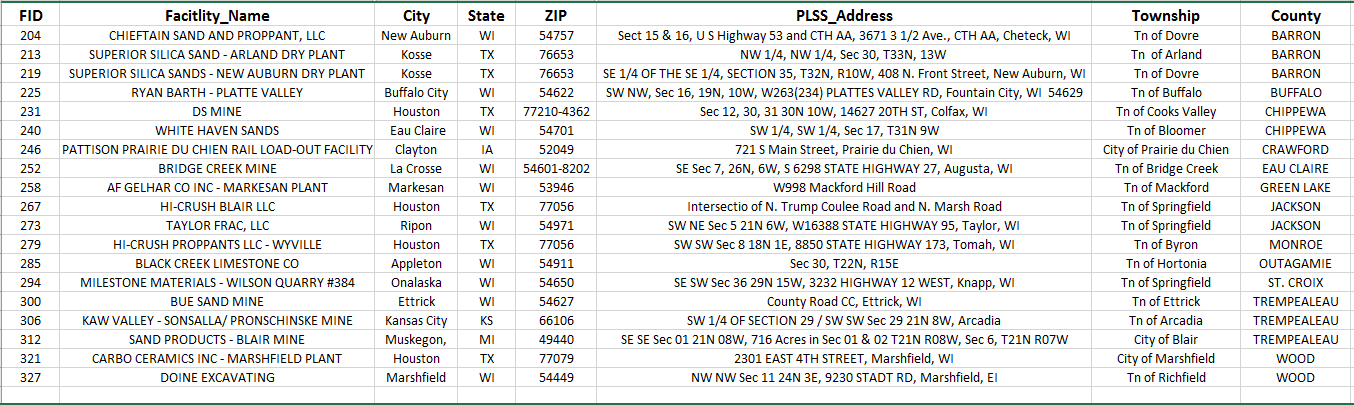
In beginning the lab, students were provided with a listed series of mines and their location information in an organized Excel file. The working list was divided up among students so that each mine site would be geocoded by approximately four students, and each student was designated approximately nineteen sand mine site locations for geocoding.
Objective One required each student to pull their assigned mines and the data associated with each from the overall class data table (shown in
Figure 1) and normalize the addresses into a separate Excel sheet file (
Figure 2). Normalizing the data required the various types of addresses and their provided components to be pieced out from the facility address field into separate, individual fields, resulting in a separate field for each of the following: PLSS location or Street Address, city, town, county, state, and zip code.
A snapshot from the resulting normalized Excel table is pictured in
Figure 2 below:
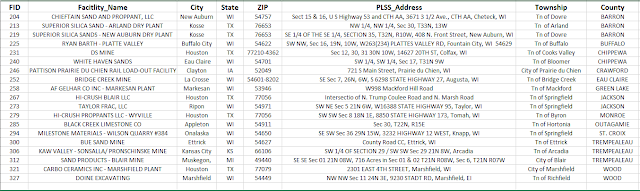 |
| Figure 2: Normalized Excel Data for Mine Sites |
With the data now normalized, students were able to proceed to
Objective Two, uploading the resulting sheet into ArcMap and logging in to ESRI's Enterprise server to enable the geocoding toolbar and begin locating each of the mine sites designated. ESRI's geocoding toolbar allows the geocoding process to be automated. The Address Inspector function located on the geocoding toolbar allows for the mine point placement, placement candidates, and the properties which were used in establishing the placement to be reviewed. After the original auto-placement of these mine sites, ArcMap generates an error table, which calculates the percent of accuracy and certainty in the mine site placement locations. The auto-placement error can be seen in
Table 1.
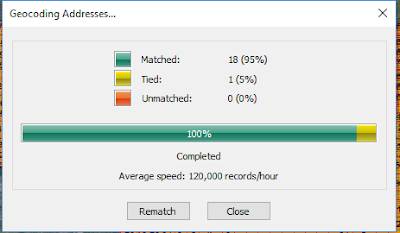 |
| Table 1: ArcMap Auto-Geocoding Error |
While in most instances the auto-locator provided by ESRI does an adequate job in geocoding the locations of inputted address sites, the process is not always exact. For example, for addresses which possess ONLY a PLSS location description (in place of an actual street address), the automated geocoded location of these mines will not be accurately placed; instead, the mine's data point will fall in the center of it's associated town or city, and must be moved to the correct location from there. This can be accomplished through the various steps denoted in
Objective Three and
Four outlined below.
 |
| Figure 3: WiDNR2014 Database Layers Added to the Map |
In phase four of the five part project, students were required to manually locate each of the remaining, unmatched mine sites using the PLSS address description and various PLSS feature class layers. Accessing these layers required the completion of the exercise's third objective: connecting with the University of Eau Claire: Geography Department's SQL Server and locating the necessary PLSS layers within the WiDNR2014 database. Once the connection was made, the layers shown in
Figure 3 were able to be added to the map as base data, and symbolized so that each layer was decipherable with a distinctive colored outline and a hollowed center, so that the imagery basemap remained visible. From there, numeric labels were added to each of the layers to help guide the placement of the manually determined and geocoded mine sites using the PLSS section, township, and quarter labels in each of the mine site addresses. Once the correct location of the sand mine was found, the "Pick Address from Map" button established the point's corrected location. The Match_Type field in the attribute table accounts for this alteration by replacing the original designated value 'A' (automated) to an 'M' (manual), signifying the change has been made. The process required all mine data point locations to be checked, and corrected where needed.
Lastly, Objective Five allowed students to compare their manual geocoding results with both the results of their peers as well as with the actual PLSS locations of the mines, while simultaneously assessing the degree of error that exists between each site placement. This task required students to merge their collected data with the class data AND the actual site location data before querying out their assigned mine IDs from the collective layer. This provided students with data for all geocoded placements for their 19 prescribed mines, their correct locations, and alternative geocoded site placements made by peers for the same mines. With this data now at hand, assessments about error can be made between each of the established placements per mine ID. Not surprisingly, each student's geocoded placements varied from the actual mine site location, at differing degrees. In order to measure the how drastic these distance differences were, a distance field needed to be added to a merged mines attribute table.
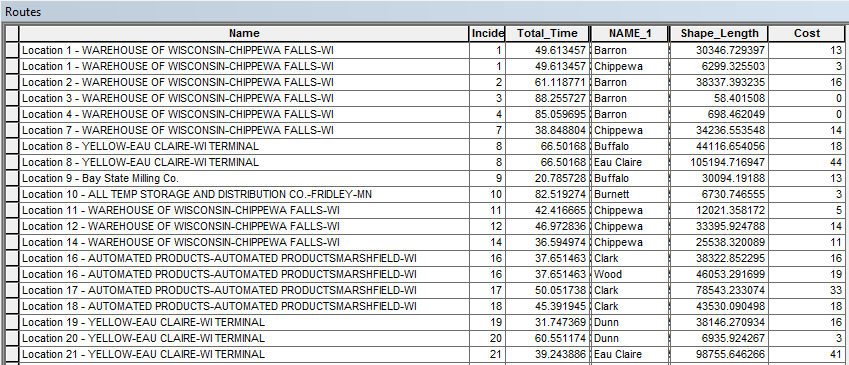
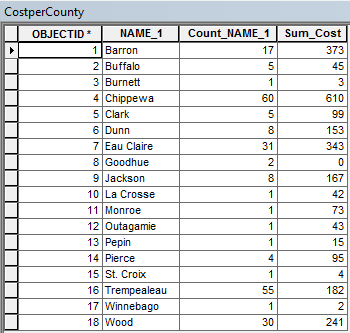
To establish this distance field, a total of three layers were pulled from the merged and queried layer representing the 19 mine IDs; these three new layers included "MyMines," "ClassMines," and "ActualMines." The "Near" tool was used twice to compare "MyMines" with "ActualMines" and "ClassMines" with "ActualMines." These results were then re-merged to reveal the distances between each geocoded mine and the actual mine site. A sample of the resulting table reporting distance error is pictured in Table 2. The first set of data refers to the self-geocoded distances results while the second set of data offers the geocoded distances of other students from the actual mine site locations.
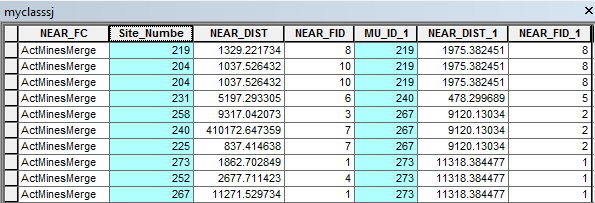 |
| Table 2: Geocoded Mine Sites Distance from Actual Mines Sites |
Results:
The final result of the 19 geocoded mines which were manually located and placed, as previously described in objective four of the methods section, is pictured in Map 1 below. The map reveals how the PLSS system was used to narrow-in on each individual mine site location. A sample of the labeled grid system is showcased in the lower left corner of the map. Each mine was located using the numbers indicating township, section, and quarter section in the mine PLSS address.
In the PLSS system, Townships are established as a square block encompassing 36 square miles. These 36 square miles are then split into 36 individual square mile fragments that account for the 36 Sections. Each section, then, can be split further into four quarter sections. Directional values in the PLSS address indicate which of the section's four quadrants the mine in question is located in.
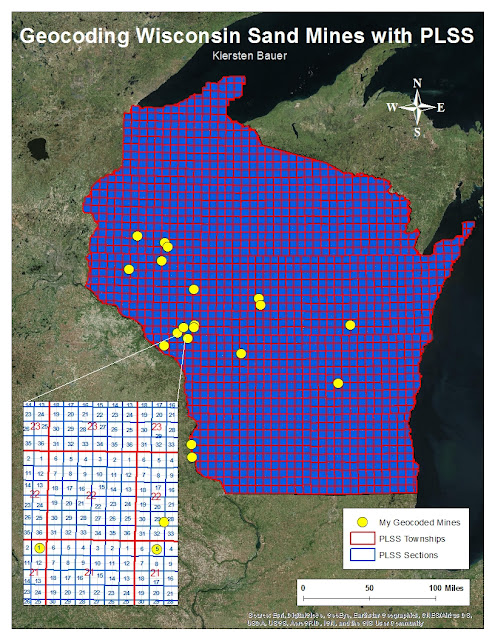 |
| Map 1: Geocoding Wisconsin Sand Mines with PLSS |
The final placement of geocoded mine sites appear to be mostly in the western half and northcentral fragment of the state of Wisconsin, many clustered near the La Crosse and Eau Claire areas. The placement of these each of these mine sites can be compared to the correlating mine results of the class and the actual location of each mine in Map 2.
 |
| Map 2: Wisconsin Sand Mines: Geocoding Error Sample Map |
Map 2 makes an attempt to visually produce the distance error was calculated in Table 2
of the methods section. It reveals the geocoding distances between a sample of manually self-plotted mines, some classmates same manually plotted mines, and the actual location of the mine. Hollowed stars mark the actual location of the sampled sand mines while varying colored circles represent the collective self- and peer- geocoded locations. The color of each point reveals how closely the plotted points were to the actual mine site locations. Green points symbolize close proximity to the actual location of the mine (between 480 and 1.300 feet), while red points symbolize the greatest amount of plotted distance error (12,000+ feet from the actual mine site location). Each plotted location includes a label of the mine's ID to match the geocoded locations with the actual locations accordingly. Pink text for the mine ID indicates a classmate's plotted geocode, while blue mine ID text showcases the self-attempts. Some of the clustered areas have been blown up and re-scaled for a more detailed distribution of the mine sites.
In analyzing the overall spatial distribution of the plotted mine sights, it seems that most of the plotted mine sites generally lie in near proximity to the mine site's actual location (within a mile of the target site, or symbolized by the first three distance ranges in the map's legend). As evident within the map's data, there was not always a classmate attempt to compare to for each of the mine sites produced. In this sampled section, only four of their contributions are made apparent for comparison. Some outliers in the data include mine ID 240, whose red color symbolizes a large distance error from the actual mine site, which can be located approximately 410,000 feet north of the attempted plotted site. This error was likely made due to misreading the PLSS address details. A second error is evident with the actual plotted site 213, for which there are no corresponding geocoded attempts, neither self-made or peer-produced. This error was also likely due to human error in piecing out a sample of the 19 mine site IDs to showcase for the error map.
Discussion:
The readings on Lo's "Data Quality and Data Standards" discusses the difference between accuracy and precision in a geographic context. Accuracy is a measure of how closely the data and attributes between the representation and the real world resemble one another. Precision, on the other hand, makes a determination of how exact the location measurement of the representative data resembles to the location of the actual data as it exists in the real world. Many of the mines situated in clusters near to one another show an example of precision error. Mines in these instances are placed in near proximity to one another, but it would be nearly impossible to pin-point the exact placement of the points determining the actual mine. An example of accuracy error can be seen with the plotted mines distanced far from one another. Mines such as Mine Site 240 show two separate locations which in no way should resemble one another. Of the three error types: gross, systemic and random, that which is most apparent here are likely to be gross error, or errors which could be avoided with a few more random checks of the plotted data.
Conclusion:
This lab offered students the opportunity to familiarize themselves with two different types of geocoding and the potential errors that can arise from its use. Having an awareness of these potential errors will prove useful in future geocoding activities which may arise in later projects so that these errors can hopefully be avoided. The exercise was also a good activity for reviewing the PLSS system and learning how to navigate the overall grid system to find various mine site locations. Further analysis on each of these mine sites will be made in future blogs to come in completing the Trempealeau County Sand Mine class project through additional class organized exercises.

















{kind=link}